Slurm workload manager, formerly known as Simple Linux Utility For Resource Management (SLURM), is an open source, fault-tolerant, and highly scalable resource manager and job scheduling system of high availability currently developed by SchedMD. Initially developed for large Linux Clusters at the Lawrence Livermore National Laboratory, Slurm is used extensively on most Top 500 supercomputers around the globe.
If you have questions about job dispatch priorities on the Fermilab LQCD clusters then please visit this page or send us an email with your question to hpc-admin@fnal.gov.
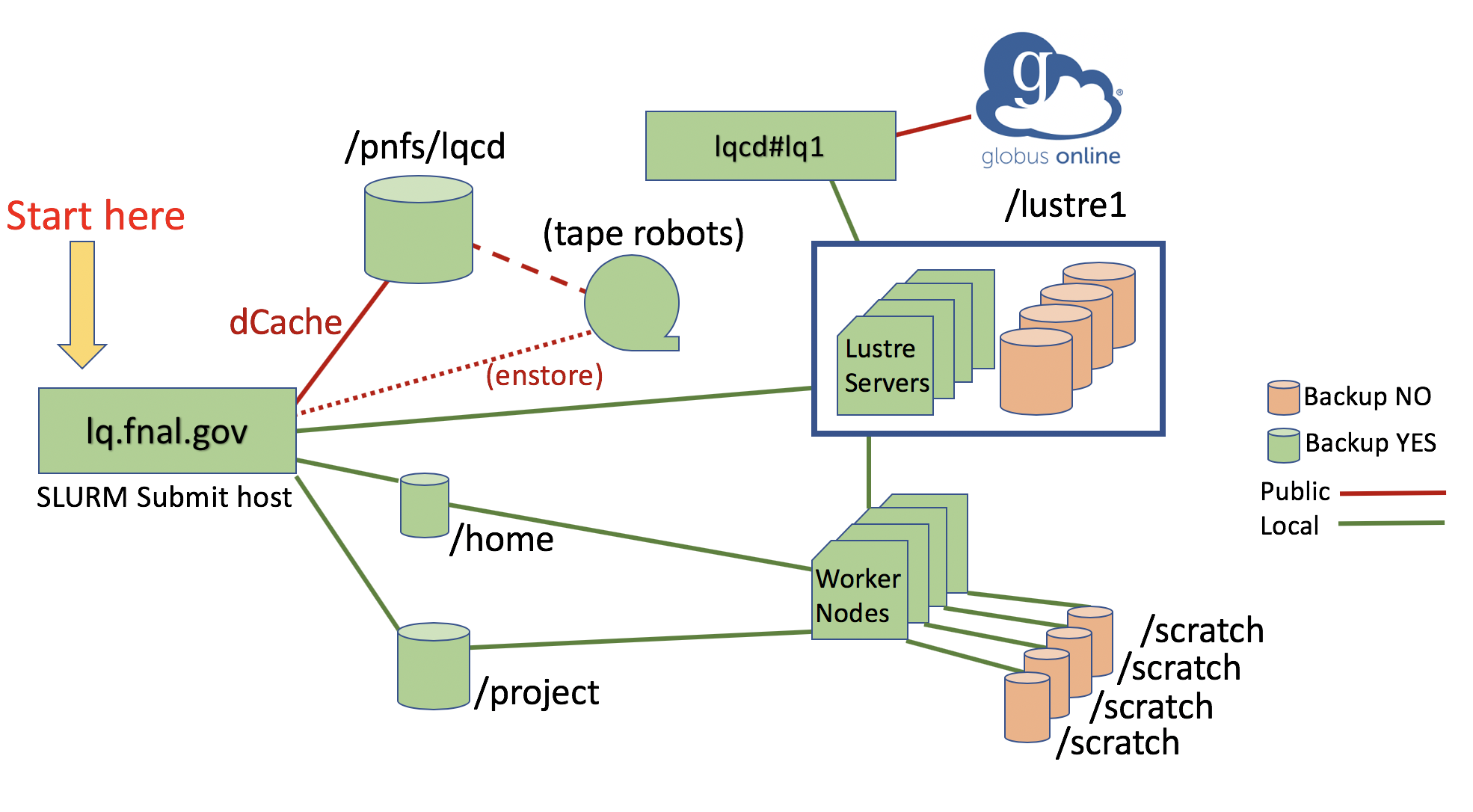
Slurm Commands
One must log in to the appropriate submit host (see Start Here in the graphics above) in order to run Slurm commands for the appropriate accounts and resources.
scontrolandsqueue: Job control and monitoring.sbatch: Batch jobs submission.salloc: Interactive job sessions are request.srun: Command to launch a job.sinfo: Nodes info and cluster status.sacct: Job and job steps accounting data.- Useful environment variables are
$SLURM_NODELISTand$SLURM_JOBID.
Slurm User Accounts
In order to check your “default” Slurm account use the following command:
[@lq ~]$ sacctmgr list user name=johndoe
User Def Acct Admin
---------- ---------- ----------
johndoe project None
To check “all” the Slurm accounts you are associated with use the following command:
[@lq ~]$ sacctmgr list user name=johndoe withassoc User Def Acct Admin Cluster Account Partition Share Priority MaxJobs MaxNodes MaxCPUs MaxSubmit MaxWall MaxCPUMins QOS Def QOS ---------- ---------- --------- ---------- ---------- ---------- --------- ---------- ------- -------- -------- --------- ----------- ----------- -------------------- --------- johndoe projectx None lq projecta 1 opp,regular,test opp
Slurm Resource Types
For details on available resource types and their associated constraints, please visit this page. In summary, resources are available across two partitions and through three different Slurm QoS as shown in table below.
| Partition name | Resource type | Number of resources | Available QoS | Slurm directives for access |
| lq1_cpu | 2.50GHz Intel Xeon Gold 6248 “Cascade Lake“, 196GB memory per node (4.9GB/core), EDR Omni-Path | 179 worker nodes with 40 CPU cores each | normal (for approved allocations) opp (for opportunistic usage) test (for quick testing) | For partition selection:--partition=lq1_cpuNode allocation is done using the standard directives like --nodes, --ntasks-per-node etc. |
| lq2_gpu | NVIDIA A100 GPU nodes | 18 worker nodes with 4 GPUs each | normal (for approved allocations) opp (for opportunistic usage) test (for quick testing) | For partition selection:--partition=lq2_gpuTo request two GPUs: --gres=gpu:2OR --gres=gpu:a100:2OR --gpus=a100:2 |
Using Slurm: examples
Submit an interactive job requesting 12 worker nodes :
[@q:~]$ srun --pty --nodes=12 --ntasks-per-node=40 --partition lq1_cpu bash [user@lq1wn001:~]$ env | grep NTASKS SLURM_NTASKS_PER_NODE=40 SLURM_NTASKS=480 [user@lq1wn001:~]$ exit
Submit a batch job requesting 4 worker nodes :
[@lq ~]$ cat myscript.sh #!/bin/sh #SBATCH --job-name=test #SBATCH --partition=lq1_cpu #SBATCH --nodes=4 # print hostname of worker node hostname sleep 5 exit [@q ~]$ sbatch myscript.sh Submitted batch job 46
Once the batch job completes the output is available as follows :
[@lq ~]$ cat slurm-46.out lq1wn053.fnal.gov
Submit a batch job requesting 2 GPUs :
[@lq ~]$ cat myscript.sh
#!/bin/sh
#SBATCH --account=scd_csi.lq2_gpu
#SBATCH --qos=normal
#SBATCH --partition=lq2_gpu
#SBATCH --gpus=a100:2
# print hostname of worker node
hostname
sleep 5
exitSlurm Reporting
The lquota command run on lq.fnal.gov will provide allocation usage reporting as shown below.
[amitoj@lq ~]$ lquota Last Updated on: Tue Feb 23 15:00:01 CST 2021 |--------------- |--------------------- |-------------- |--------------- |-------- | Account | Used Sky-ch on LQ1 | Pace | Allocation | % Used | | since Jul-1-2020 | MM-DD-YYYY | in Sky-ch | |--------------- |--------------------- |-------------- |--------------- |-------- | chiqcd | 7,825,317 | Jun-29-2021 | 11,992,366 | 65% | gluonpdf | 18,525 | Jan-4-2038 | 500,000 | 4% | hadstruc | 3,269,152 | Apr-26-2021 | 4,137,963 | 79% | hiq2ff | 36 | Dec-15-3822 | 100,000 | 0% | lattsusy | 452,441 | May-11-2021 | 600,000 | 75% | lp3 | 6,178,070 | Oct-23-2021 | 12,500,000 | 49% <---snip--->
lq1-ch=lq1-core-hour , Sky-ch=Sky-core-hour ,1 lq1-ch=1.05 Sky-ch
For questions regarding the reports or should you notice discrepancies in data please email us at hpc-admin@fnal.gov
Slurm Environment Variables
| Variable Name | Description | Example Value | PBS/Torque analog |
| $SLURM_JOB_ID | Job ID | 5741192 | $PBS_JOBID |
| $SLURM_JOBID | Deprecated. Same as SLURM_JOB_ID | ||
| $SLURM_JOB_NAME | Job Name | myjob | $PBS_JOBNAME |
| $SLURM_SUBMIT_DIR | Submit Directory | /project/charmonium | $PBS_O_WORKDIR |
| $SLURM_JOB_NODELIST | Nodes assigned to job | lq1wn00[1-5] | cat $PBS_NODEFILE |
| $SLURM_SUBMIT_HOST | Host submitted from | lq.fnal.gov | $PBS_O_HOST |
| $SLURM_JOB_NUM_NODES | Number of nodes allocated to job | 2 | $PBS_NUM_NODES |
| $SLURM_CPUS_ON_NODE | Number of cores/node | 8,3 | $PBS_NUM_PPN |
| $SLURM_NTASKS | Total number of cores for job | 11 | $PBS_NP |
| $SLURM_NODEID | Index to node running on relative to nodes assigned to job | 0 | $PBS_O_NODENUM |
| $SLURM_LOCALID | Index to core running on within node | 4 | $PBS_O_VNODENUM |
| $SLURM_PROCID | Index to task relative to job | 0 | $PBS_O_TASKNUM – 1 |
| $SLURM_ARRAY_TASK_ID | Job Array Index | 0 | $PBS_ARRAYID |
Binding and Distribution of tasks
There’s a good description of MPI process affinity binding for srun here: Click here
A reasonable distribution / affinity choice for the lq1_cpu partition of the Fermilab LQCD clusters is:
srun --distribution=cyclic:cyclic --cpu_bind=sockets --mem_bind=no
Launching MPI processes
Please refer to the following page for recommended MPI launch options.