The Software Program Committee allocates resources during each program year. Each project is allocated a certain number of hours on various resources such as CPU core hours, GPU hours or time on an Institutional Cluster. We use a Slurm feature called QoS (Quality of Service) to manage access to partitions by projects and job dispatch priority. This is all part of maintaining a Fair Share usage of allocated resources.
Slurm prioritization
The only prioritization that is managed by Slurm is the dispatch or scheduling priority. All users submit their jobs to be run by Slurm on a particular resource, such as a partition. On a billable or allocated partition, the projects that have allocated time available should run before those that do not have an allocation. This is true regardless of whether it is a Type A, B or C allocation. An unallocated project is said to be running opportunistically.
Partitions at Fermilab
We currently have two partitions within the Fermilab Lattice QCD Computing Facility as shown in the table below. Both these partitions are billable against an allocation. There are limits in place to make sure that at least two (in some cases three) projects can be active at any given time. These limits are enforced through Slurm QoS as described in the next section.
| Name | Description | Billable | Total Nodes | Maximum Runtime | Default Runtime |
| lq1_cpu | LQ1 CPU CascadeLake | Yes | 179 | 1-00:00:00 | 8:00:00 |
| lq2_gpu | LQ2 A100 GPU cluster | Yes | 18 | 1-00:00:00 | 8:00:00 |
Both these partitions are accessible from the login node (lq.fnal.gov) and can be selected using the --partition directive of Slurm submit commands like sbatch and srun.
Slurm QoS defined at Fermilab
Jobs submitted to Slurm are associated with an appropriate QoS (or Quality of Service) configuration. Admins assign parameters to a QoS that are used to manage dispatch priority and resource use limits.
| Name | Description | Priority | Global Resource Constraints | Max Walltime | Per Account Constraints | Per User Constraints |
| admin | admin testing | 600 | None | None | None | None |
| test | quick tests of scripts | 500 | Max nodes = 2 Max GPUs = 4 | 00:30:00 | Max jobs = 3 | Max jobs = 1 |
| normal | QoS available to accounts with allocations | 250 | None | 1-00:00:00 | Max jobs = 125 Max nodes = 128 Max GPUs = 40 | None |
| opp | QoS available to all accounts for opportunistic usage | 10 | None | 08:00:00 | Max jobs = 125 Max nodes = 64 Max GPUs = 4 | None |
A few notes about the resource constraints:
- Global resource constraints are enforced across all the accounts in the cluster. For example,
testQoS restricts access to 4 GPUs globally. If accountAis using 4 GPUs, accountBhas to wait until the resources are freed up. - Per account constraints are enforced on an account basis. For example,
normalQoS restricts access to 128 nodes. If userAin accountXis using 128 nodes, userBhas to wait until resources are freed up. UserCbelonging to a different accountYcan continue to run in such a scenario. - Similarly, per user constraints are enforced on a user basis. For example,
testQoS restricts the number of jobs per user to 1. This means a single user, regardless of their account, cannot submit more than a single job using the QoS. - Finally, these constraints may be relaxed or adjusted from time to time based on the job mix and to maximize cluster utilization.
A few notes about available QoS:
- Users can select QoS appropriately by using
--qosdirective with their submit commands. The default QoS for all projects isopp. Jobs running under this QoS have the lowest priority and will only start when there aren’t any eligiblenormalQoS jobs waiting in the queue. When a project uses up all of the hours that they were allocated for the program year, their jobs will be limited to theoppQoS. - We have defined the
testQoS for users to run small test jobs to see that their scripts work and their programs run as expected. These test jobs run at a relatively high priority so that they will start as soon as nodes are available. Any user can have no more than three jobs submitted and no more than one job running at any given time. - The
normalQoS is only available to projects (or accounts) with approved allocations. As long as an account is under their resource constraint limits, their jobs are scheduled as soon as resources become available.
Slurm Commands to see current priorities
To see the list of jobs currently in queue by partition, visit our HPC cluster status monitoring and select the LQCD Cluster Status dashboard. By default jobs are sorted by their state but clicking on different column headers changes the sorting. We also provide a Username filter up top to view queued jobs for a given user. You can see the submit time, start time and end time for jobs along with their associated priorities on the dashboard.
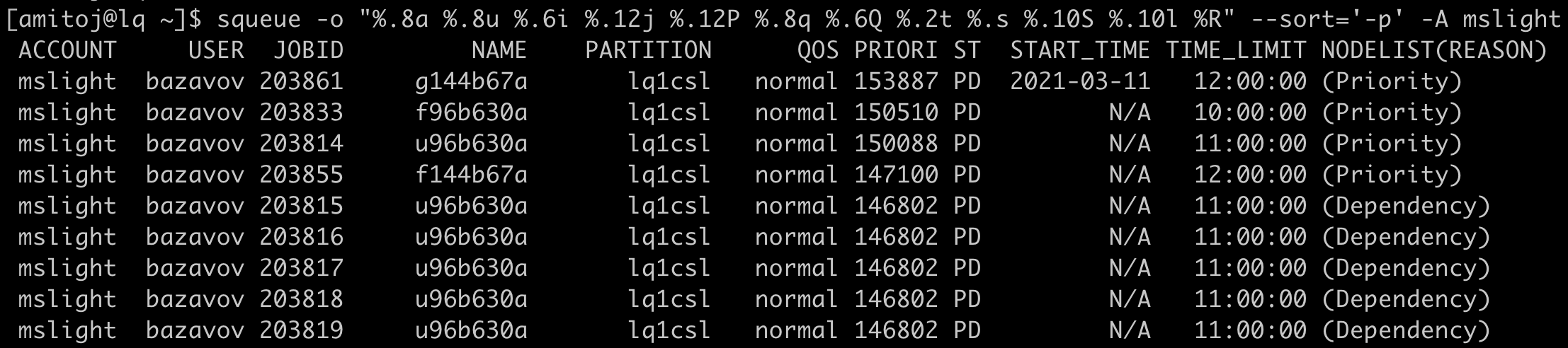
From a command line, Slurm’s ‘squeue‘ command lists the jobs that are queued. It includes running jobs as well as those waiting to be started, or dispatched. By changing the format of the command output, one can get a lot of information about several things such as:
- Start time – actual or predicted
- QoS the job is running under
- Reason that the job is pending
- Calculated dispatch real-time priority of the job
The following is just a sample output. Use your project name after the “-A” option to get a listing of jobs for your account.