Slurm workload manager, formerly known as Simple Linux Utility For Resource Management (SLURM), is an open source, fault-tolerant, and highly scalable resource manager and job scheduling system of high availability currently developed by SchedMD. Initially developed for large Linux Clusters at the Lawrence Livermore National Laboratory, Slurm is used extensively on most Top 500 supercomputers around the globe.
Caveat concerning batch job submission
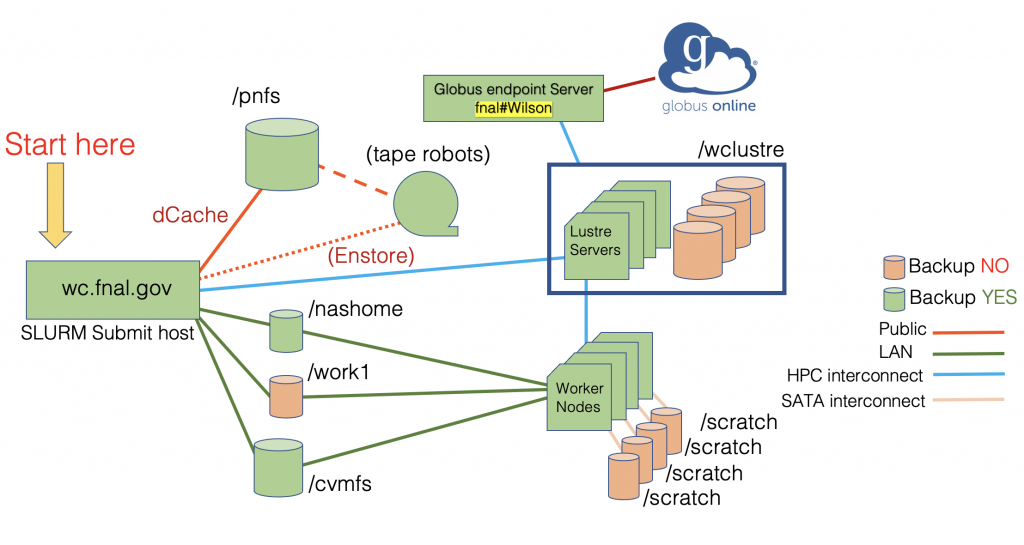
Please note that Slurm batch jobs will NOT run from your home directory on the Wilson cluster!
Your Wilson home directory, $HOME, is your lab-wide “nashome” directory. The /nashome filesystem is mounted with Kerberos authentication, and unfortunately, Kerberos is not compatible with Slurm. Start batch jobs from your area under either /work1 or /wclustre.
Common Slurm commands
| command | brief description |
| squeue | reports the state of queued jobs |
| sbatch | submit a job script for later execution |
| scancel | cancel a pending or running job |
| scontrol | view or modify Slurm configuration and state |
| salloc | allocate resources and spawn a shell which is then used to execute srun commands |
| srun | submit a job for execution or initiate job steps in real time |
| sacctmgr | view and modify Slurm account information |
| sinfo | worker node and partition information |
See the downloadable PDF cheatsheet for a summary of the commands. SchedMD has a quick start guide for Slurm users.
squeue examples: checking the status of batch jobs
The command below checks the status of your jobs in the queue.
$ squeue -u $USERThe following command will show jobs assigned to the wc_cpu (CPU) partition.
$ squeue -p wc_cpuThe squeue command with the options below will tell you the status of GPU batch jobs including which workers are in use, how many GPUs a job is using, the number of cores, maximum memory, how long the job has been running, and the time limit for the job.
$ squeue -p wc_gpu --Format=Account:.10,UserName:.10,NodeList:.10,tres-alloc:.64,State:.8,TimeUsed:.10,TimeLimit:.12Details about your Slurm account(s)
Every Slurm user has a default account. You can find your default with the command:
$ sacctmgr list user name=$USER
User Def Acct Admin
---------- ---------- ---------
smith wc_test NoneUsers on Wilson may have multiple Slurm accounts with different quality of service (QOS) levels. You can find all your associated accounts along with available QOS levels using the following command:
$ sacctmgr list user WithAssoc Format=User,Account,QOS,DefaultQOS name=$USER
User Account QOS Def QOS
---------- ---------- -------------------- ---------
smith hpcsoft opp,test opp
smith scd_devs opp,regular,test opp
smith spack4hpc opp,regular,test opp
smith wc_test opp,regular,test oppNOTE: If you do not specify an account name during your job submission (using --account), your default account will be used.
Quality of service (QoS) levels
Jobs submitted to Slurm are associated with an appropriate QoS (or Quality of Service) configuration. Admins assign parameters to a QoS that are used to manage dispatch priority and resource use limits.
| Name | Description | Priority (higher is better) | Global Resource Constraints | Max Walltime | Per Account Constraints | Per User Constraints |
| admin | admin testing | 100 | None | None | None | None |
| test | for quick user testing | 75 | Max nodes = 5 Max GPUs = 4 | 04:00:00 | None | Max running jobs = 1 Max queued jobs = 3 |
| regular | regular QoS for approved accounts | 25 | None | 1-00:00:00 | None | None |
| walltime7d | only available to certain approved accounts | 25 | Max nodes = 50 | 7-00:00:00 | None | None |
| opp | available to all accounts for opportunistic usage | 0 | None | 08:00:00 | None | Max queued jobs = 50 |
A few notes about the resource constraints:
- Global resource constraints are enforced across all the accounts in the cluster. For example,
testQoS restricts access to 4 GPUs globally. If accountAis using 4 GPUs, accountBhas to wait until the resources are free. - Per account constraints are enforced on an account basis. We currently do not have per account constraints on Wilson cluster.
- Per user constraints are enforced on a user basis. For example,
testQoS restricts the number of running jobs per user to 1. This means a single user, regardless of their account, cannot run more than a single job using the QoS. - Finally, these constraints may be relaxed or adjusted from time to time based on the job mix and to maximize cluster utilization.
A few notes about available QoS:
- Users can select QoS appropriately by using
--qosdirective with their submit commands. The default QoS for all accounts isopp. Jobs running under this QoS have the lowest priority and will only start when there aren’t any eligibleregularQoS jobs waiting in the queue. - The
testQoS is for users to run test jobs for fast turnaround debugging. These test jobs run at a relatively high priority so that they will start as soon as nodes are available. Any user can have no more than three jobs submitted and no more than one job running at any given time. - All Wilson users have opportunistic access to batch resources. Compute projects with specific scientific or engineering goals are able to request access to higher QoS level and more compute resources.
NOTE: if you do not specify a QOS during job submission (using --qos), the default opp will be used.
Slurm partitions
A partition in Slurm is a way to categorize worker nodes by their unique features. On the Wilson cluster we distinguish workers meant for CPU computing from GPU-acclerated workers. There is a separate partition for the one IBM Power9 “Summit-like” worker since the Power9 architecture is not binary compatible with the common AMD/Intel x86_64 architecture. There is also a test partition to set aside CPU workers for rapid testing. Slurm allows setting job limits by partition.
| Name | Description | Total Nodes | Default Runtime | Exclusive Access |
| wc_cpu | CPU workers 2.6 GHz Intel E5-2650v2 “Ivy Bridge”, 16 cores/node, 8GB/core memory, ~280GB local scratch disk, inter-node QDR (40Gbps) Infiniband | 90 | 08:00:00 | Y |
| wc_cpu_test | CPU workers 2.6 GHz Intel E5-2650v2 “Ivy Bridge”, 16 cores/node, 8GB/core memory, ~280GB local scratch disk, inter-node QDR (40Gbps) Infiniband | 7 | 01:00:00 | Y |
| wc_gpu | GPU workers Several types of GPUs such as V100, P100, A100. More details in Table 4 below | 7 | 08:00:00 | N |
| wc_gpu_ppc | IBM Power9 with GPUs (V100) | 1 | 08:00:00 | N |
The desired partition is selected by specifying the --partition flag in a batch submission. On Wilson, the CPU workers are scheduled for exclusive use by a single job. The default is that the GPU workers permit shared use by mutiple jobs / users. The option --exclusive can be used to request that a job be given exclusive use of the worker nodes.
Slurm job dispatch and priority
Slurm on Wilson cluster primarily uses QoS to manage partition access and job priorities. All users submit their jobs to be run by Slurm on a particular resource within one of several partitions. We do not use any form of preemption on our cluster. The resource constraints we have in place are to ensure that multiple projects or accounts can be active on the cluster at any given time and to ensure fair share of available resources.
To see the list of jobs currently in the queue by partition, visit our cluster status page. Click on the “Start Time” column header to sort the table by start time. Don’t be alarmed if you see dates from 1969 for idle jobs. This just means Slurm hasn’t gotten to those jobs yet and monitoring is showing the default.
For running jobs, “Start Time” is the actual time that the jobs started. Following that are the pending jobs in the predicted order they may start. You can also click on the “Submit Time” column header to see which jobs have been waiting the longest. There are filters in the top right corner to select partitions and users.
From a command line, Slurm’s ‘squeue‘ command lists the jobs that are queued. It includes running jobs as well as those waiting to be started, aka dispatched. By changing the format of the commands output, one can get a lot of information about several things, such as:
- Start time – actual or predicted
- QoS the job is running under
- Reason that the job is pending
- Calculated dispatch real-time priority of the job
The following command should return a sorted (by priority) list of your jobs:
$ squeue --sort=P,-p --user=$USERThe following command uses the --Format option of squeue to provide even more details. You can tweak the decimal point values to adjust column width. The Slurm squeue manual page here has details on the options for --Format.
$ squeue --sort=P,-p --Format=Account:.10,UserName:.10,JobID:.8,Name:.12,PriorityLong:.10,State:.5,QOS:.8,SubmitTime:.20,StartTime:.20,TimeLimit:.11,Reason:.15 --user=$USERSpecifying the number and type of GPUs in a job
All GPU worker nodes are in the wc_gpu partition except the IBM Power9 worker which is in the wc_gpu_ppc partition. The WC has GPU worker nodes with different generations of NVIDIA GPUs. The “Slurm spec” in the table below is how how you tell Slurm the GPU type you want. If you do not specify a type, you job will run with first available GPU of any type.
| nodes | GPU type | CUDA cores / GPU | device memory [GB] | Slurm spec | GPUs / node | CPU cores / GPU | Memory/ GPU (GB) |
| 2 | A100 | 6912 | 80 | a100 | 2 | 32 | 256 |
| 1 | A100 | 6912 | 80 | a100 | 4 | 16 | 126 |
| 4 | V100 | 5120 | 32 | v100 | 2 | 20 | 92 |
| 1 | P100 | 3584 | 16 | p100 | 8 | 2 | 92 |
| 1 | P100 | 3584 | 16 | p100nvlink | 2 | 14 | 500 |
| 1 | V100 | 5120 | 32 | v100nvlinkppc64 | 4 | 8 (32 threads) | 250 |
A GPU job can request more than one GPU to enable parallel GPU use by your code. Slurm, however, will not permit mixing different Slurm specifications within a job, e.g., a job cannot request eight V100 plus eight P100 devices. GPUs on a worker are partitioned by jobs up to the limit of the maximum number of GPUs in a node. Each job is assigned exclusive of its GPUs, an individual GPU is never shared by different jobs.
Slurm manages GPUs as generic resource via the --gres flag to the commands sbatch, salloc, or srun. The table below shows examples of how to choose GPUs in a batch submission.
| Slurm options | Description |
--gres=gpu:1 | one GPU per node of any type |
--gres=gpu:p100:1 | one P100 GPU per node |
--gres=gpu:v100:2 | two V100 GPUs per node — the max on the Intel V100 workers |
--gres=gpu:v100:2 --nodes=2 | total of four V100 GPUs, requires two worker nodes |
For the latter two examples, the submission request should include the --exclusive option since the request asks for all GPUs on the worker nodes.
The batch system is configured to portion out CPU and RAM to each batch job. GPU jobs are assigned default values --cpus-per-gpu=2 and --mem-per-gpu=30G. Jobs may request more than the default values. Users should override the defaults using the suggested Cores/GPU and Mem/GPU values in the above table.
Interactive jobs
Interactive job on CPU-only workers
The command below starts an interactive batch job.
- The job uses a single worker node of the
wc_cpu(CPU-only) partition. - The job is run under the Slurm account
myAccountatregularQoS. - The job requests a time limit of 50 minutes.
- The job requests one task and 16 CPUs per task. Specifying CPUs per task is important for threaded applications. If the single task runs 16 threads, they will be able to use all 16 cores on this worker. Other combinations of nodes, tasks and cores per task are acceptable.
- Since CPU-only workers are not shared among jobs, available compute resources are usually maximized by choosing
ntasks * cpus-per-task = nodes * SLURM_CPUS_ON_NODE.
$ cd /work1_or_wclustre/your_projects_directory/
$ srun --unbuffered --pty --partition=wc_cpu --time=00:50:00 \
--account=myAccount --qos=regular \
--nodes=1 --ntasks=1 --cpus-per-task=16 /bin/bash
$ hostname
wcwn001.fnal.gov
$ env | grep -e TASKS -e CPUS -e CPU_BIND_
SLURM_CPU_BIND_VERBOSE=quiet
SLURM_CPUS_PER_TASK=16
SLURM_TASKS_PER_NODE=1
SLURM_STEP_TASKS_PER_NODE=1
SLURM_NTASKS=1
SLURM_JOB_CPUS_PER_NODE=16
SLURM_CPUS_ON_NODE=16
SLURM_CPU_BIND_LIST=0xFFFF
SLURM_CPU_BIND_TYPE=mask_cpu:
SLURM_STEP_NUM_TASKS=1
$ exit # end the batch job
$ hostname
wc.fnal.govInteractive job on a GPU node
The command which follows request a one-hour interactive job on a GPU worker. In this example, we specify a single GPU device of type V100 using the syntax from Table 5. The request also specifies the number of CPU cores and system RAM per GPU from Table 4 for the V100 worker nodes. Specifying no more than the maximum values of cores and memory per GPU listed in Table 4 will fairly share these resources among jobs that may share the worker node.
$ srun --unbuffered --pty --partition=wc_gpu --time=01:00:00 \
--account=myAccount --qos=regular \
--nodes=1 --ntasks=1 \
--gres=gpu:v100:1 --cpus-per-gpu=20 --mem-per-gpu=92G \
/bin/bash
$ hostname
wcgpu04.fnal.gov
$ nvidia-smi --list-gpus
GPU 0: Tesla V100-PCIE-32GB
$ env | grep -e TASKS -e CPUS -e CPU_BIND_ -e GPU_
SLURM_CPU_BIND_VERBOSE=quiet
SLURM_TASKS_PER_NODE=1
SLURM_STEP_TASKS_PER_NODE=1
SLURM_NTASKS_PER_NODE=1
SLURM_CPUS_PER_GPU=20
SLURM_NTASKS=1
SLURM_JOB_CPUS_PER_NODE=20
SLURM_CPUS_ON_NODE=20
SLURM_CPU_BIND_LIST=0x003FF003FF
SLURM_CPU_BIND_TYPE=mask_cpu:
SLURM_STEP_NUM_TASKS=1
GPU_DEVICE_ORDINAL=0Batch jobs and scripts
Slurm can run a sequence of shell commands specified within a batch script. Typically many such scripts specify a set of parameters for slurm at the top of the script file. These parameters are prefaced by #SBATCH at the beginning of the lines.
Running a simple CPU batch script
In this example we request a single CPU-only worker node and request four tasks and four CPU cores per task. The product equals the sixteen cores on these workers. This combination of tasks and cores per task is typical when running a total four MPI ranks where each MPI rank will run four threads.
$ cat batch_cpu.sh
#! /bin/bash
#SBATCH --account=myAccount
#SBATCH --qos=test
#SBATCH --time=00:15:00
#SBATCH --partition=wc_cpu
#SBATCH --nodes=1
#SBATCH --ntasks=4
#SBATCH --cpus-per-task=4
#SBATCH --job-name=cpu_test
#SBATCH --mail-type=NONE
#SBATCH --output=job_%x.o%A
#SBATCH --no-requeue
hostname
env | grep -e TASKS -e CPUS -e CPU_BIND_
We submit the batch job with the command below
$ sbatch batch_cpu.shThis example produced a batch output fine named job_cpu_test.o527837 in the directory where the job was submitted. The ouput is shown below.
$ cat job_cpu_test.o527837
wcwn026.fnal.gov
SLURM_CPUS_PER_TASK=4
SLURM_TASKS_PER_NODE=4
SLURM_NTASKS=4
SLURM_JOB_CPUS_PER_NODE=16
SLURM_CPUS_ON_NODE=16Running a simple GPU batch script
In this example, we will run a batch script called batch_gpu.sh. The cat command that follows displays the content of this file. Note that this job requests a single V100 GPU a “fair share” of CPU cores and host memory per GPU on the shared GPU worker.
$ cat batch_gpu.sh
#! /bin/bash
#SBATCH --account=myAccount
#SBATCH --qos=test
#SBATCH --time=00:15:00
#SBATCH --partition=wc_gpu
#SBATCH --nodes=1
#SBATCH --ntasks=1
#SBATCH --gres=gpu:v100:1
#SBATCH --cpus-per-gpu=20
#SBATCH --mem-per-gpu=92G
#SBATCH --job-name=gpu_test
#SBATCH --mail-type=NONE
#SBATCH --output=job_%x.o%A
#SBATCH --no-requeue
hostname
nvidia-smi --list-gpus
env | grep -e TASKS -e CPUS -e CPU_BIND_ -e GPU_We submit this script to slurm
$ sbatch batch_gpu.shThe job will be placed in the batch queue and upon job completion the directory where the job was submitted contains a file named job_gpu_test.o527838. Below we display the result form this job.
$ cat job_gpu_test.o527838
wcgpu04.fnal.gov
GPU 0: Tesla V100-PCIE-32GB (UUID: GPU-dca4cd4b-03e3-1021-36d2-916a1e59be96)
SLURM_TASKS_PER_NODE=1
SLURM_CPUS_PER_GPU=20
SLURM_NTASKS=1
SLURM_JOB_CPUS_PER_NODE=20
SLURM_CPUS_ON_NODE=20
GPU_DEVICE_ORDINAL=0Running MPI application under slurm
Please refer to the XXXXX for instructions on running MPI in batch jobs.
There’s a good description of MPI process affinity binding and srun here: task binding and distribution.
Developer access to GPU workers
Several of A100, V100, and P100 equipped GPU workers are reserved for use by GPU developers during weekday business hours (09:00-17:00 M-F). This reservation is intended to provide developers rapid access to GPUs for testing without having to wait for long batch jobs to finish. Both interactive and batch job access is permitted on the reserved nodes. Jobs must include the parameter --reservation=gpudevtest to access the reserved nodes. The reservation is only available to members of a special GPU developer project and the batch request must include --project=scd_devs. Users wishing to be added to the developer group must complete the user request form asking to be added to project scd_devs. Please provide a detailed justification for you request in the reason field of the request form. Approval is subject to review of your justification.
Slurm Environment variables
The table below list some of the commonly used environment variables. A full list is found in the Slurm documentation for sbatch.
| Variable Name | Description | Example Value | PBS/Torque analog |
| $SLURM_JOB_ID | Job ID | 5741192 | $PBS_JOBID |
| $SLURM_JOB_NAME | Job Name | myjob | $PBS_JOBNAME |
| $SLURM_SUBMIT_DIR | Submit Directory | /work1/user | $PBS_O_WORKDIR |
| $SLURM_JOB_NODELIST | Nodes assigned to job | wcwn[001-005] | cat $PBS_NODEFILE |
| $SLURM_SUBMIT_HOST | Host submitted from | wc.fnal.gov | $PBS_O_HOST |
| $SLURM_JOB_NUM_NODES | Number of nodes allocated to job | 2 | $PBS_NUM_NODES |
| $SLURM_CPUS_ON_NODE | Number of cores/node | 8,3 | $PBS_NUM_PPN |
| $SLURM_NTASKS | Total number of cores for job | 11 | $PBS_NP |
| $SLURM_NODEID | Index to node running on relative to nodes assigned to job | 0 | $PBS_O_NODENUM |
| $PBS_O_VNODENUM | Index to core running on within node | 4 | $SLURM_LOCALID |
| $SLURM_PROCID | Index to task relative to job | 0 | $PBS_O_TASKNUM – 1 |
| $SLURM_ARRAY_TASK_ID | Job Array Index | 0 | $PBS_ARRAYID |
Slurm fixed reservation requests
Projects that require access to Wilson cluster resources within a fixed period of time or before a fixed deadline are able to request ahead a reservation for a designated amount of compute resources. Examples where projects may benefit from having a reservation in place include:
- Making Wilson compute resources available to a workshop or a hackathon.
- Having high-priority access to Wilson computing to meet a high-priority deadline such as preparation of a scientific paper or conference presentation.
Reservations should not be considered unless there is a well-defined need that cannot be met by the standard batch system queuing policies. Reservation requests are carefully reviewed on their scientific and engineering merit and approval is not automatic. A reservation request must be made though a service desk request using this link. Requests should be made at least two business days in advance of the reservation start date. Your request must contain at least the following
- Name of your Wilson cluster computing project
- Supervisor name(s)
- Name of the event requiring a Slurm reservation
- Type of event, e.g., workshop, presentation, paper publication
- Date and time ranges of the Slurm reservation
- Type (cpu or gpu) and number of workers to be reserved
- Justification for a special batch reservation. In particular, why do the normal batch policies not meet your needs.