NOTICE: The Wilson Cluster will be decommissioned beginning June 28, 2024
All HPC services provided by the Wilson cluster will cease. Users will have to consider alternatives for their computing needs. Users must migrate their data from the NFS project filesystem /work1 and off of /wclustre to another storage system. Slides about the alternatives to the Wilson cluster from the June 11, 2024 meeting with Wilson users are on indico.
Timeline
| Date | Milestone |
| 2024-06-28 | End all batch operations |
| 2024-07-15 | Deadline to transfer data out of /wclustre |
| 2024-07-15 | Deadline to transfer data out of /work1 |
Decommissioning updates:
- 2024-06-12 — Ceph disk areas are mounted on data transfer node wcio.fnal.gov. Use wcio to copy data you wish to keep from
/work1or/wclustreto your organization’s Ceph area. See the file transfer tips below. - 2024-06-11 — Wilson cluster all hands meeting slides
File transfer tips
Copy to your orgainization’s Ceph areas from either /work1 or /wclustre
Direct copies can be done from the Wilson cluster data transfer server wcio.fnal.gov since the experiment Ceph areas, work1, and Lustre are all mounted there. Login to wcio.fnal.gov to do your copies. We recommend using rsync with the archive option enabled (rsync -a). When doing long copies we recommend using a tmux terminal session to avoid copy interruptions from terminal disconnects. From wcio the Ceph areas are mounted as /exp, Lustre is mounted as /GRIDFTPROOT/wclustre, and the NFS work partition is /GRIDFTPROOT/work1. You can view your orgainization’s Ceph quotas in landscape from the CephFS Usage page. Please coordinate with your organization’s computing liaison on managing your organization’s Ceph areas and where you should put your data. Ceph is operated by the Scientific Data Services department. Questions about quotas or issues affecting Ceph operations should be filed in Service Now (Ceph).
Globus copies offsite (e.g. to NERSC)
Instructions for using Globus transfers are here. Search for the Wilson cluster globus endpoint which is called “Wilson Cluster Globus Endpoint” from the file manager page endpoint search box. The Wilson endpoint uses CILogon for authentication. The NERSC instructions for accessing their Globus endpoints are here. Please be aware that the current storage allocation at NERSC was intended for staging data and is not suitable for parking your data long term.
Introduction




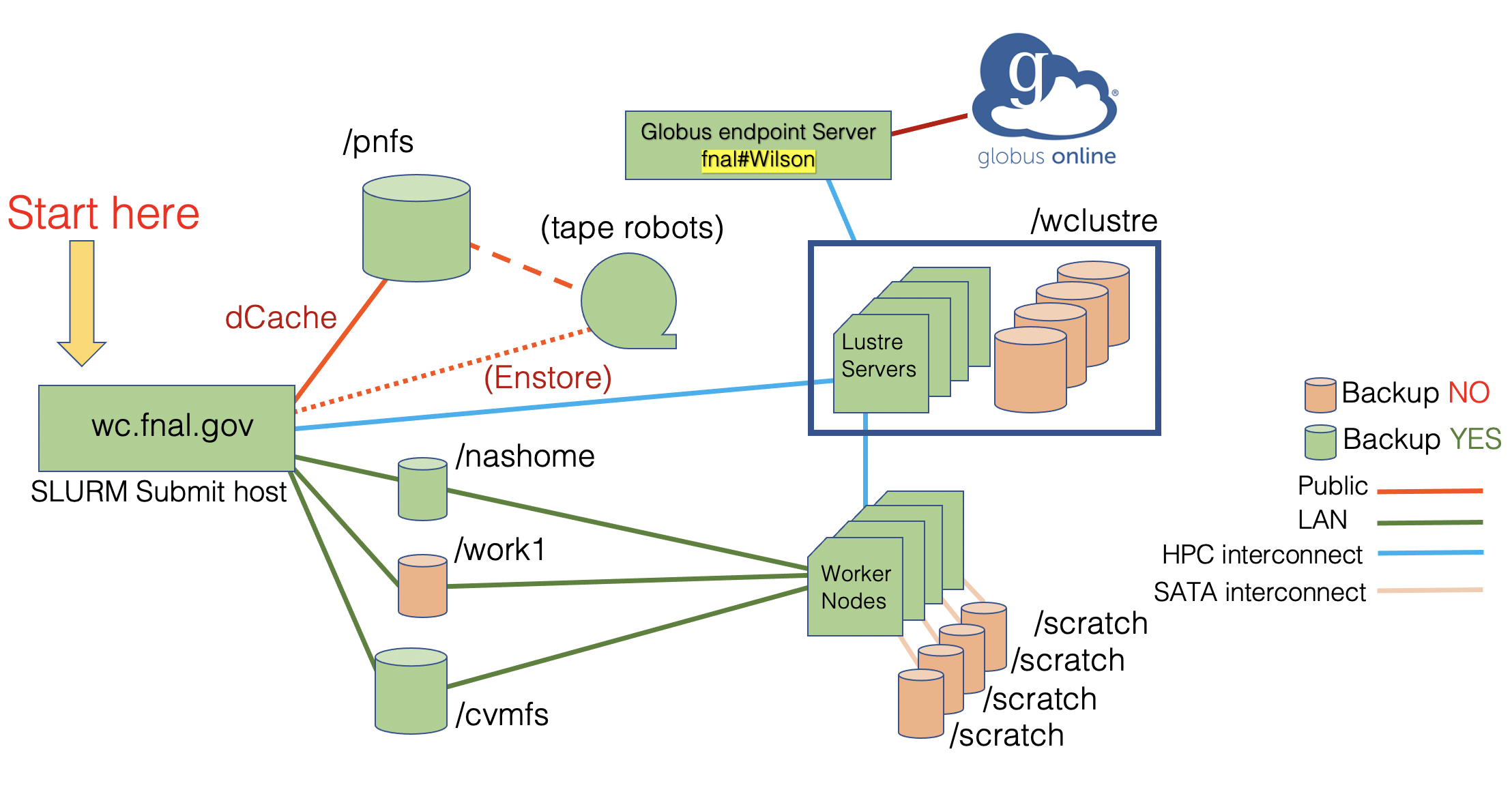
The Wilson cluster (WC) is a High-Performance Computing (HPC) cluster available to the entire Fermilab scientific and engineering community. The WC is designed to be able to efficiently run and scale up parallel workloads over hundreds CPU cores and/or multiple GPUs. The Wilson cluster provides HPC services typical of larger HPC centers such as NERSC, OLCF, or ALCF. The WC is considered a medium-scale HPC facility which can provide a development on-ramp to the larger HPC centers.
Features include:
- Up to O(800) CPU cores per job for tightly coupled parallel computations (MPI, OpenMP, …).
- Access to multiple A100, V100, and P100 NVIDIA GPUs (CUDA, NVIDIA HPC sdk).
- Workers equipped with multiple GPUs to efficiently scale jobs to multiple GPUs.
- Ability to run containerized HPC and AI applications with Apptainer.
- High-bandwidth, low-latency InfiniBand networking among workers and storage.
- High-performance Lustre parallel filesystem for efficient access large data sets and files.
- NFS
/work1filesystem allowing shared access among users in the same compute project. - Slurm batch system designed to run HPC workloads at scale.
- Optional interactive access to worker nodes via a shell launched by slurm.
- High-bandwidth data transfer node with Globus for transfers among data centers.
- Access to the CernVM-FS software distribution service.
Use cases for include:
- Code development and performance testing of parallel CPU codes.
- GPU code development including the ability to test performance while running on multi-GPUs.
- AI model training when the convergence of HPC and AI features are critical to performance.
- Testbed to rapidly explore new algorithms and methods with minimal barriers to getting started and obtaining the needed computing resources.
- Platform for modest small to medium scale non-critical parallel computing campaigns.
- A development on-ramp for HPC workflows to be run at scale at larger HPC centers.
- A reservable compute resource for workflows with tight deadlines or for use during hands-on workshops.
Q&A
- Who has access to Wilson? In short, everyone within the Fermilab community having a Kerberos identity has opportunistic access to cluster resources. Opportunistic access means your HPC jobs run at lower priority and have more restrictive limits on compute resources.
- How do I obtain resources beyond what opportunistic access permits? Groups of users that have scientific or engineering goals that require more resources are asked to provide justification and apply for a Wilson project account. See Projects and User Requests.
- How do I login to the Wilson Cluster? Use ssh to login to either
wc.fnal.govorwc2.fnal.gov. - Is my workload suitable for Wilson? Wilson is specifically designed to efficiently run High Performance (HPC) workloads consisting of tightly coupled parallel applications. Examples of HPC applications include Lattice QCD, computational fluid dynamics, molecular dynamics simulations, and training large AI models. If your workload, instead, consists of many independent single-core tasks that can execute concurrently or in a distributed manner, then a High Throughput Computing (HTC) facility such as HepCloud or FermiGrid is better matched to your needs.
- What are the advantages doing AI training on Wilson? Jobs on Wilson are provided whole data center GPU devices, not a partition of a device, or a lower performance “gamer” GPU. Large training jobs can take advantage of training on multiple GPUs. Lustre and InfiniBand provide low-latency high-bandwidth access to very large data sets.
- I prefer to use JupyterHub for my computing, can I run Jupyter on Wilson? Yes, it is indeed possible to run Jupyter from Wilson worker nodes and login nodes via ssh tunneling, but it requires extra steps and you may need to wait in a batch queue before your session starts on a worker. Please note that Wilson does not officially support this mode operation. Fermilab offers the Elastic Analysis Facility specifically designed for JupyterHub. Note that VPN is required to access EAF offsite.
Schematic layout